TensorFlow のオブジェクト検出APIの環境(Windows, Ubuntu)ができましたので、TensorFlow のオブジェクト検出APIのチュートリアルを参考にして、フォルダ内の画像ファイルからの動物の検出と画像の切り出しを行う簡単な Python サンプルプログラムを自作してみました。
(練習のためのサンプルプログラムです。詳細の動作確認は行っていません。)
(1)概要
画像からの動物の検出と画像の切り出しを行うサンプルプログラム。
1.選択されたフォルダ内の画像ファイルより物体の検出を行う。
2.元の画像にラベルを付加した画像を出力する。
3.検出された物体が特定の動物ならば、その部分を切り取りファイルとして出力する。
出力されるファイル
・元画像にラベルを書き込んだファイル: labeled_元画像ファイル名
・検出されたオブジェクトを切り出した画像ファイル: クラス名_元画像ファイル名_番号_スコア
このプログラムは TensorFlow 2 Object Detection API tutorial の Example を参考にして作成されています
(2)プログラム
Pythonプログラム(テキストファイル UTF-8)
searchimage.py
(3)解説
選択抽出対象となるクラスはダウンロードした mscoco_label_map.pbtxt から動物のクラスを選択しました。
ここでの動物名は生物的な分類名ではなく世俗的な名前です。
定義
TARGET_CLASSES = [
[16, “bird” ], # 鳥
[17, “cat” ], # 猫
[18, “dog” ], # 犬
[19, “horse” ], # 馬
[20, “sheep” ], # 羊
[21, “cow” ], # 牛
[22, “elephant”], # 象
[23, “bear” ], # 熊
[24, “zebra” ], # 縞馬
[25, “giraffe” ] # 麒麟
]
画像のあるフォルダの選択処理は、tkinterを利用しました。
import tkinter.filedialog as filedialog
imageDirWk = filedialog.askdirectory(title=”画像フォルダ選択”, initialdir=defaultDir)
書き込み先フォルダの選択処理も同様に、tkinterを利用しました。
outputDirWk = filedialog.askdirectory(title=”書き込み先のフォルダ選択”, initialdir=defaultDir)
オブジェクト検出モデルのダウンロードやラベルのダウンロードは、ほぼチュートリアルのとおりです。
オブジェクト検出結果のクラスの配列から目的(TARGET_CLASSES)を検出する処理は以下のようにしました。
スコアが 0.3 より大きく、検出された画像サイズが 10 x 10 より大きい場合を切り出すことにしています。
classArray = detections[‘detection_classes’]
for item in TARGET_CLASSES :
indexes = np.where(classArray == item[0])
for index in indexes[0] :
box = detections[‘detection_boxes’][index]
score = detections[‘detection_scores’][index]
if score > 0.3 : # スコアが一定以上を対象にする
# 該当範囲を切り出す
boxImage = getBoxImage(imageNpWithDetectons, box)
h, w, c = boxImage.shape
if h > 10 and w > 10 : # 画像サイズが一定以上を対象にする
画像の検出結果から画像を切り出す処理は配列の処理を使っています。
def getBoxImage(img, box) :
h, w, c = img.shape
sx = int(box[1] * w)
sy = int(box[0] * h)
ex = int(box[3] * w)
ey = int(box[2] * h)
return img[sy:ey, sx:ex]
(4)動作確認
テストデータ一覧

実行結果一覧
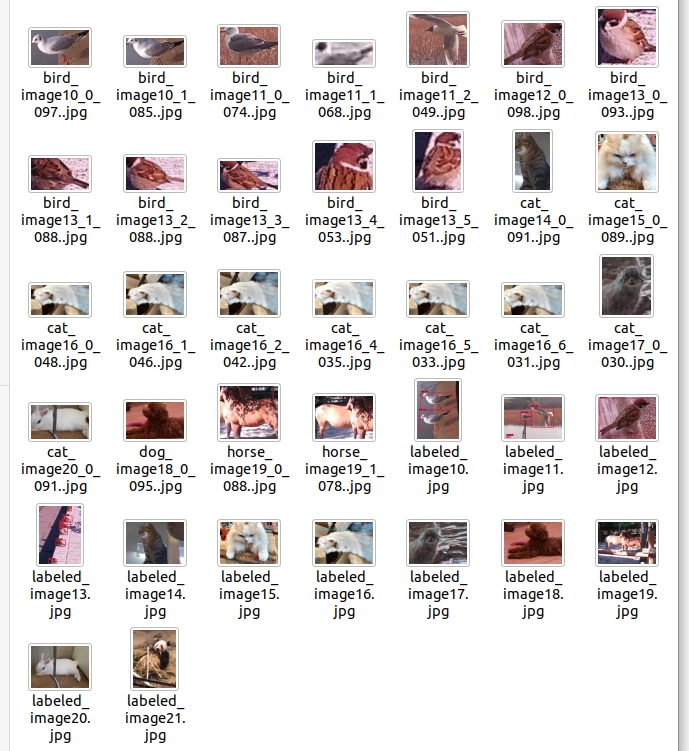
検出された画像の例

切り出された画像の例


![]()
結果を見ると、マヌルネコ(野生のネコ)は”cat”として検出されています。

猫の手の画像も”cat”として正しく検出されましたが同じような画像は複数出ています。

クラス定義にない動物では、ウサギが”cat”扱いされて、ジャイアントパンダは対象外でラベルなしとなりました。
その他は期待通りの結果となりました。
今回利用した学習済みモデルは世俗的な分類で生物の種類も少ないですので、
今後の課題としては ecobio らしく、より多様で詳細な生物画像データで再学習を行い検出することです。
(2024/01/01 Shin Onda)
(2024/02/24 Shin Onda 一部修正)
